SCHEDA DELL'INSEGNAMENTO (SI)
SSD ING-INF/05
LAUREA MAGISTRALE IN INGEGNERIA INFORMATICA
ANNO ACCADEMICO: 2022-2023

INFORMAZIONI GENERALI - DOCENTE
DOCENTE: PAOLO MARESCA
TELEFONO: +39 081 7683168
EMAIL: Questo indirizzo email è protetto dagli spambots. È necessario abilitare JavaScript per vederlo.
INFORMAZIONI GENERALI - ATTIVITÀ
INSEGNAMENTO INTEGRATO (EVENTUALE):
MODULO (EVENTUALE):
CANALE (EVENTUALE):
ANNO DI CORSO (I, II, III): II
SEMESTRE (I, II): II
CFU: 6
INSEGNAMENTI PROPEDEUTICI
(se previsti dall'Ordinamento del CdS)
...................................................................................................................................................
EVENTUALI PREREQUISITI
...................................................................................................................................................
OBIETTIVI FORMATIVI
Obiettivo dell’insegnamento è quello di fornire le conoscenze e competenze approfondite necessarie per la comprensione di sistemi basati sul paradigma del cognitive computing. Il cognitive computing è una disciplina emergente che, mettendo insieme conoscenze di cloud, Big Data, IOT, connessioni fra le reti, machine learning, natural language processing, AI, deep learning e knowledge representation, sviluppa sistemi automatici che cercano di simulare il processo del pensiero umano. Gli studenti avranno anche l'opportunità di maturare le competenze specialistiche necessarie per lo sviluppo di applicazioni cognitive che possono interagire con persone e/o cose (macchine e/o altri computer). Il corso sarà corredato da una attività di esercitazione e sviluppo di applicazioni in laboratorio.
RISULTATI DI APPRENDIMENTO ATTESI
(Descrittori di Dublino)
Conoscenza e capacità di comprensione
Lo studente deve essere in grado di conoscere le tematiche e le problematiche ricomprense in questo corso fino al punto di elaborare connessioni trasversali fra le discipline che il cognitive computing ricomprende. Il paradigma del cognitive computing è dirompente (disruptive) perché introduce uno sconvolgimento nel modo di procedere nel risolvere problemi e nel progettare soluzioni di fronte a problemi che spaziano in molte tematiche e su molti domini applicativi. L’insegnamento fornirà gli strumenti metodologici per elaborare ed applicare questo nuovo paradigma su casi concreti.
Capacità di applicare conoscenza e comprensione
Lo studente sarà in grado, da solo o in gruppo, di ideare, progettare e realizzare una applicazione cognitiva. Egli acquisirà gli strumenti metodologici propri del paradigma del cognitive computing e li applicherà al dominio applicativo designato. La sua capacità nel dominare la pervasività delle applicazioni cognitive sarà importante per applicare concretamente le conoscenze maturate nel corso. Allo scopo di implementare correttamente una soluzione, esperienze provenienti dalle aziende più quotate in ambito mondiale faranno da traccia nella maturazione degli strumenti metodologici all’avanguardia nelle aziende e nei centri di ricerca.
PROGRAMMA-SYLLABUS
Il programma sarà composto dai seguenti argomenti
• An overview of Artificial Intelligence and Machine Learning
• Natural Language Understanding
• Approaches to automated question answering and relation extraction
• The foundation of cognitive computing
• Design principles of cognitive computing and Design Thinking
• Cognitive computing ecosystem scenario
• Applying Advanced Analytics to cognitive computing
• Unstructured Information Management Architecture & Massively Parallel Probabilistic Evidence-Based architecture
• The Cognitive computing paradigm
• Cooperative cognitive programming & Flow-Based programming
• The role of cloud and distribute computing in CC: PaaS platform as IBM-Watson, Microsoft-Azure, et al
• Building a Watson-enabled system
• The process of Building a cognitive application
• Applications of cognitive computing to Internet of Things
• The operation of AI platforms
• Efficient use of resources
• Responsible AI
• Approach that combines small data & wide data
• New trends in Cognitive computing
An overview of artificial intelligence and machine learning
In questo capitolo si fornisce una overview di intelligenza artificiale e di machine learning percorrendo la sua traccia nella ricerca negli ultimi 50 anni. La visione attuale di IA è quella di Intelligenza Aumentata. In altri termini l'IA non dovrebbe tentare di sostituire gli esseri umani, ma piuttosto assistere e amplificare la loro intelligenza. Possiamo usare l'intelligenza aumentata per estendere le capacità umane e realizzare cose che né gli uomini né le macchine potrebbero fare da soli. Alcune delle sfide che affrontiamo oggi provengono da un eccesso di informazioni. Internet ha portato a comunicazioni più veloci e all’accesso a una grande quantità di informazioni. Il calcolo distribuito e l'IoT hanno portato alla generazione di enormi quantità di dati e il social networking ha fatto si che la maggior parte di quei dati non siano strutturati. Ci sono così tanti dati che gli esperti umani non possono tenere il passo con tutti i cambiamenti e i progressi nei loro campi di studio: insomma non abbiamo un piano per utilizzarli! Con l’intelligenza aumentata o allargata (Augmented Intelligence), vogliamo mettere le informazioni di cui gli esperti hanno bisogno a portata di mano e restituire tali informazioni con una probabilità di correttezza, in modo che gli esperti possano prendere decisioni più informate. Vogliamo che gli esperti aumentino le loro capacità in modo che possano migliorare il servizio ai propri clienti. Vogliamo lasciare che le macchine facciano il lavoro dispendioso in termini di tempo in modo che gli esperti siano in grado di fare le cose che contano. Una delle sfide importanti è che l’intelligenza artificiale, sostituendo gli uomini nelle attività ripetitive di tutti i giorni, dovrà essere accettata in moltissimi campi della vita e del lavoro delle persone. I dati che vengono raccolti riguardano persone, elettrodomestici, automobili, reti, assistenza sanitaria, decisioni di acquisto, meteo, comunicazioni e tutto ciò che vediamo. È anche più facile che mai avere accesso a questi dati grazie agli smart phone e gli smart watch, gli utenti li usano per pubblicare immagini dei loro prodotti alimentari, acquisti di negozi ed esercizi di routine sui social media. Quando sviluppiamo sistemi di IA, dobbiamo stabilire fiducia. Si pone subito un problema che è : se non ti fidi di una macchina che fornisce delle raccomandazioni non puoi fidarti dei consigli che ti dà. Se qualcuno ti dà consigli, dobbiamo avere un livello di fiducia costruito prima di seguirli. Un modo per creare fiducia è mostrare come è stata costruita la raccomandazione (trasparenza). Qualsiasi soluzione che utilizza l'intelligenza artificiale dovrebbe essere costruita tenendo conto della trasparenza e della divulgazione. La privacy è un'altra preoccupazione che deve essere affrontata fin dall'inizio quando si costruisce una soluzione di intelligenza artificiale. Una volta persa la privacy, non puoi recuperarla. Poi ci sono i problemi etici che l’uso della IA crea Le sfide etiche ci sono sempre state nel momento in cui la tecnologia ha fatto passi avanti: si pensi ai primi anni della televisione etc., non ci meraviglia che questo accada oggi con l’IA. Semplicemente dobbiamo accettare queste sfide. Insomma un mondo stimolante e alla avanguardia ci aspetta in questo corso.
Natural language Understanding
Il linguaggio naturale è il modo con il quale gli esseri umani esprimono concetti, esigenze, sentimenti, etc. Esso rappresenta lo strumento di comunicazione principale. Sembra naturale ed ovvio iniziare da questo potente strumento per iniziare un viaggio attraverso lo studio e l’uso di questo per istruire macchine affinche facciano ciò che noi desideriamo esse facciano. Ma il linguaggio naturale o parlato ha molte sfumature: dialetti, toni, abbreviazioni, metafore, modi di dire, etc. I nativi della lingua parlata non hanno problemi a parlare e a scrivere tutto ciò ma per le macchine è tutta un altra storia. La PNL è uno dei sottocampi più importanti dell'apprendimento automatico per una serie di ragioni. Il linguaggio naturale è l'interfaccia più naturale tra un utente e una macchina. Una trattazione rigorosa porterebbe via un intero corso, ci basterà capire quali sono i punti interessanti della ricerca e come il linguaggio sia importante nel progettare sistemi cognitivi che interagiscono con l’utente e siano in grado di risolvere problemi di complessità sempre più crescente. Vedremo come questa complessità avrà un impatto sulle architetture hardware e software che supportano le applicazioni.
Approches to automated question answering and relation extraction
Nel 2007, IBM Research ha affrontato la grande sfida di costruire un sistema informatico in grado di competere con i campioni al gioco di Jeopardy !, Un quiz televisivo televisivo statunitense. Nel 2011, il sistema di risposta alle domande a dominio aperto, denominato Watson, ha battuto i due giocatori con il punteggio più alto in un incontro di due partite Jeopardy!
I progressi nella tecnologia di risposta alle domande (QA) aperte possono aiutare i professionisti a prendere decisioni critiche e tempestive in aree quali: conformità agli standard, sanità, integrità aziendale, business intelligence, knowledge discovery, gestione della conoscenza aziendale, sicurezza e assistenza clienti, ect.
Per realizzare un progetto di tale complessità serve una architettura adeguata. l'architettura del sistema di risposta alle domande (QA) progettata per consentire a Watson-IBM di giocare a Jeopardy! come DeepQA. DeepQA è un'architettura software per l'analisi approfondita dei contenuti e il ragionamento basato sull'evidenza. Rappresenta una potente capacità che utilizza l'elaborazione avanzata del linguaggio naturale (PNL), il recupero delle informazioni, il ragionamento e l'apprendimento automatico. La filosofia alla base dell'approccio di ricerca che ha portato a DeepQA è che la vera intelligenza emergerà dallo sviluppo e dall'integrazione di molti algoritmi diversi, ciascuno guardando i dati da diverse prospettive. Il successo del sistema di risposta alle domande di Watson può essere attribuito all'integrazione di una varietà di tecnologie di intelligenza artificiale.
L'architettura DeepQA vede il problema della risposta automatica alle domande come un compito di generazione e valutazione di ipotesi massicciamente parallele. DeepQA può essere visto come un sistema che genera un'ampia gamma di possibilità e, per ciascuna, sviluppa un livello di fiducia raccogliendo, analizzando e valutando le prove basate sui dati disponibili.
Il principio computazionale primario supportato dall'architettura DeepQA può essere riassunto nei seguenti punti:
1. Assumere e perseguire molteplici interpretazioni della domanda.
2. Generare molte risposte o ipotesi plausibili.
3. Raccogliere e valutare molti percorsi di prove concorrenti che potrebbero supportare o confutare tali ipotesi.
The foundation of cognitive computing computing
Il capitolo affronta il paradigma del cognitive computing e perchè esso è differente da quello deterministico da cui discendono tutti i linguaggi di programmazione che lo studente conosce. Un paradigma basato sui dati piuttosto che sugli algoritmi e che si alimenta con una quantità sempre più crescente e mutevole di dati che esigono sistemi di calcolo paralleli e sempre più performanti. I dati cambiano velocemente. Ma perché questi dati crescono così velocemente ? perchè IL NOSTRO MODELLO SOCIALE E CAMBIATO. Le parole-chiavi che descrivono bene il modello di società in cui viviamo sono: mobile, sociotecnico, complesso e iperconnesso.
Una tecnologia cognitiva che si basa sul modo di ragionare dell’essere umano, in particolare quando un essere vivente osserva fenomeni e prende delle decisioni segue un approccio costituito da 4 passi. Ad esempio quando noi ci troviamo ad osservare qualche cosa e siamo chiamati a prendere una decisione (es. se salire le scale o prendere l’ascensore), il processo mentale che seguiamo è il seguente
1) osserviamo i fenomeni visibili e raccogliamo le prove oggettive,
2) usiamo quello che conosciamo per interpretare ciò che osserviamo generando ipotesi su ciò che viene osservato
3) valutiamo quali ipotesi sono giuste e quali sono sbagliate,
4) prendiamo la decisione scegliendo l’ipotesi che riteniamo giusta ed agendo di conseguenza
Un sistema cognitivo si comporta allo stesso modo e costituirà, una rivoluzione tecnologica e culturale che sconvolgerà diversi settori in quanto sarà in grado di operare con i big data, adoperando il cloud, IOT e le reti.
I settori di sperimentazione di un sistema cognitivo sono healthcare, travel transportation, economics, retail . Ma un sistema cognitivo può essere usato anche nella didattica ad esempio per personalizzare l’apprendimento e modificare il percorso formativo degli studenti.
Design principles of cognitive computing and design thinking
Il disegno di un Sistema cognitivo richiede molte fasi. Richiede la comprensione dei dati, l’identificazione del tipo di domande che bisogna porre e la creazione di un corpus sufficientemente completo da supportare la generazione di ipotesi, relativamente al dominio sotto esame, di fatti osservati. Insomma un sistema cognitivo è molto diverso da un sistema software perché è disegnato per creare ipotesi a partire da dati, analizzare alternative alle ipotesi stesse e determinare la disponibilità di prove a supporto per risolvere un problema. Bisogna costruire un nuovo modello di processo per le applicazioni cognitive perché debba accedere gestire ed analizzare dati in un determinato contesto applicativo, generi e misuri molte ipotesi (soluzioni) rilascino per ognuno prove a supporto ed indizi sul livello di confidenza, il sistema stesso si aggiorni continuamente non appena si aggiornano i dati in modo da diventare sempre più intelligente. Per progettare un sistema così complesso e con una spiccata personalizzazione sul dominio applicativo è necessario uno strumento di disegno più agile e semplice: il design thinking. In breve il design thinking (Il pensiero progettuale), in una delle sue quattro declinazioni, è un approccio di problem solving finalizzato a migliorare le esperienze delle persone per comprendendere i bisogni dell’utente immaginando più soluzioni possibili per rispondere alle sue esigenze. La metodologia è enormemente creativa e si incontra naturalmente con il cognitive computing. il Design Thinking sta spingendo sempre più imprese a cambiare il loro modo di innovare progettando le applicazioni cognitive in maniera creativa e dualmente si comincia a porsi la domanda: Come possono impattare gli algoritimi di intelligenza artificiale sulle attività di Design Thinking?. UN mini corso di design thinking verrà erogato in questo corso allo scopo di riuscire a progettare una applicazione cognitiva in gruppo ed apprezzare questa metodologia innovativa.
Cognitive computing ecosystem scenario
Si tratteggia l’ecosistema vasto del cognitive computing. Ogni disciplina dirompente ne ha uno
Applying advanced analytics to cognitive computing
Il capitolo affronta un interessante convergenza fra “vecchio e nuovo”. Uno studio condotto da IBM Institute for Business Value titolato “Facing the storm: Navigating the global skill crisis, condotto con oxford economics ha interrogato 5600 ceo rappresentanti di 18 industrie, 48 paesi e 800 leaders di istituzioni governative oltrechè 1500 ricercatori in università e centri di ricerca. Il 74% degli intervistati crede che i modelli di business delle aziende non sono più sostenibili in un mercato attuale ! Vi consiglio questo documento, la ragione? Le aziende si troveranno sempre a rincorrere il mercato anzicchè anticiparlo osservando le esigenze dei clienti. Il modello di maturità dei loro processi è fragile.
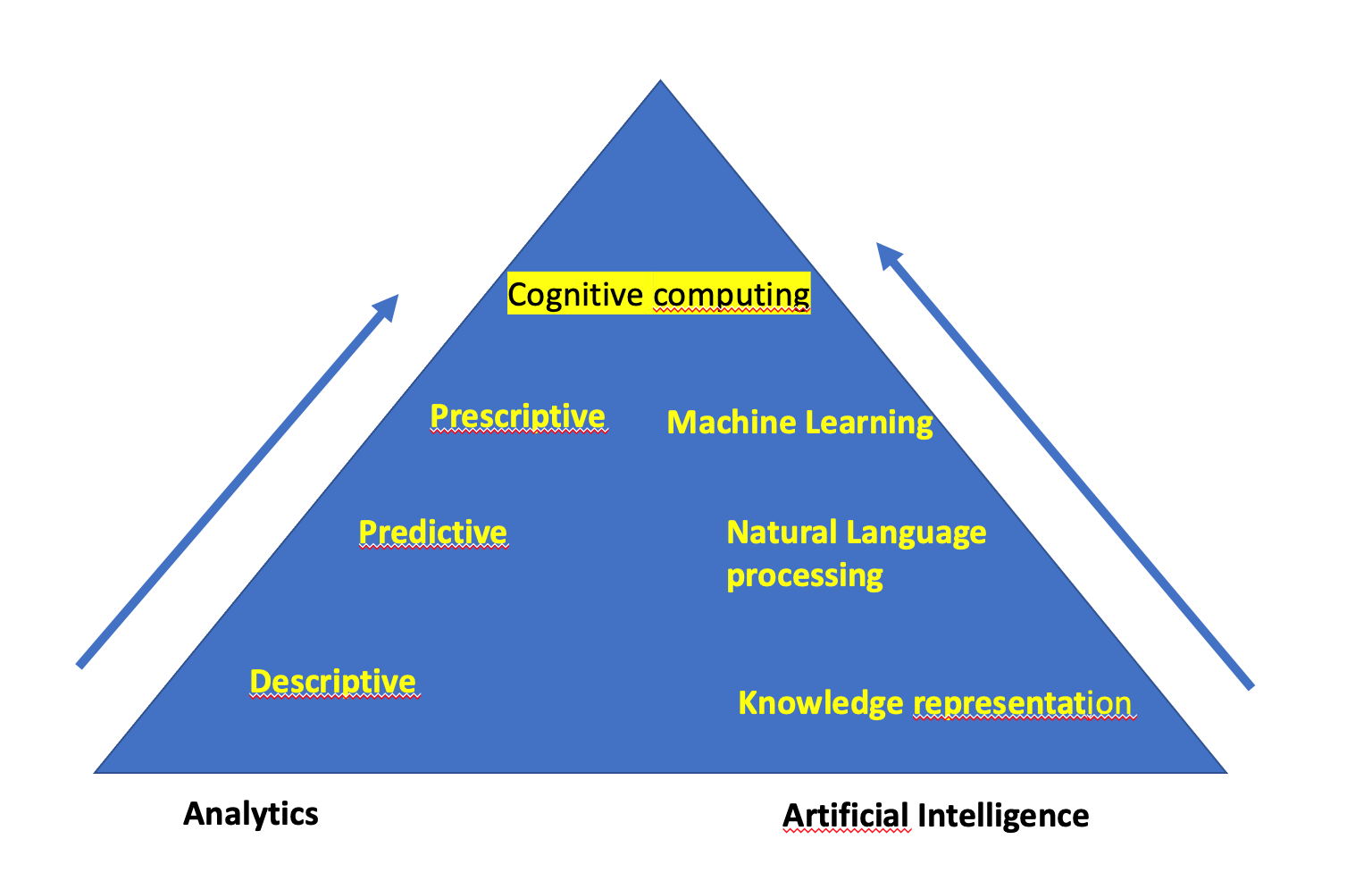
Come illustrato nella figura successiva, le aziende stanno sperimentando una progressione nel modello di maturità dell'analisi, che va dall'analisi descrittiva dall'analisi predittiva al machine learning e al cognitive computing. Le aziende che hanno avuto successo sono quelle che hanno capito come analizzare i dati per capire sia dove sono state collocate nel passato ma anche come possono imparare dal passato per anticipare il futuro. Possono descrivere in che modo azioni ed eventi avranno un impatto sui risultati. Sebbene la conoscenza di questa analisi possa essere utilizzata per fare previsioni, in genere queste previsioni sono fatte attraverso una lente di aspettative preconcette. I data scientist e gli analisti aziendali sono stati costretti a fare previsioni basate su modelli analitici basati su dati storici. Tuttavia, ci sono sempre fattori sconosciuti che possono avere un impatto significativo sui risultati futuri. Le aziende hanno bisogno di un modo per costruire un modello predittivo in grado di reagire e cambiare in caso di cambiamenti nell'ambiente. La prossima frontiera, foriera di opportunità e grossi cambiamenti, include i big data analytics ed include le tecnologie del machine learning e del cognitive computing. Come mostrato nella prossima figura c'è una convergenza di tecnologie fra l'analisi ( anche convenzionale) e l'intelligenza artificiale. Una spinta importante per questa convergenza è il cambiamento nei tempi e nell'immediatezza dei dati. Le applicazioni odierne richiedono spesso cambiamenti di pianificazione e operativi a un ritmo rapido affinché le aziende rimangano competitive. Attendere 24 ore o più per i risultati di un modello predittivo non è più accettabile. Ad esempio, un'applicazione di gestione delle relazioni con i clienti può richiedere un processo di analisi iterativo che incorpora le informazioni correnti dalle interazioni con i clienti e fornisce risultati a supporto del processo decisionale in pochi secondi, garantendo che il cliente sia soddisfatto. Pertanto, i modelli analitici devono incorporare set di grandi dimensioni che includano dati strutturati, non strutturati e in streaming per migliorare le capacità predittive. La moltitudine di fonti di dati che le aziende devono valutare per migliorare l'accuratezza del modello include database operativi, social media, sistemi di relazione con i clienti, web log, sensori e video.
Unstructured Information Management architecture & Massively parallel probabilistic evidence-based architecture
In questo capitolo si tratta dell'architettura che è stata utilizzata dal team DeepQA per costruire il sistema che ha battuto il migliore giocatore umano nel torneo Jeopardy! . Quindi è, secondo me, l'invenzione più brillante della letteratura sulla QA negli ultimi decenni.
Quindi, il motivo per cui Watson IBM funziona e perché similmente funzionano gli altri sistemi simili è perché l'Architettura DeepQA è stata elaborata in un modo molto flessibile e consente l'integrazione di una varietà di tecnologie diverse tra cui machine learning, elaborazione del linguaggio naturale e reasoning e rappresentazione della conoscenza, e quasi tutto ciò che è possibile pensare nel campo dell'intelligenza artificiale.
E prima di tutto, forse l'innovazione più importante nell'architettura DeepQA è il fatto che possiamo usare simultaneamente sia i dati strutturati che quelli non strutturati nello stessa architettura. L’architettura è ritagliabile, anche questa è una importante innovazione, a seconda del dominio ad esempio possiamo avere una versione semplificata di questa architettura DeepQA che è quella che chiamiamo la pipeline DeepQA minima. L’architettura stessa poi è tipicamente parallela perché essa deve esplorare tutte le strade (in parallelo) in quanto essa ha un approccio probabilistico basato sulle evidenze.
cooperative computing programming & Flow-based programming
La cooperazione e la collaborazione sono la sfida fondamentale per un gruppo di lavoro anche molto nutrito e decentrato a livello geografico. Interessanti gli strumenti di programmazione per attivare la cooperazione, distribuire i task, controllare i lavori e coordinare le attività, affinche lo sforzo converga nella direzione di amplificare gli sforzi in una collaborazione del team di sviluppo. Sebbene il progettista di sistemi cognitivi, scrive poco codice deve riusarne parti e coordinare molte librerie questo rende essenziale usare piattaforme mature per lo sviluppo. Eclipse rappresenta una di queste per la sua capacità di ospitare tutti i linguaggi AI (phyton, R, etc) oltre che tutti i linguaggi di programmazione più tradizionali con i quali moti algoritmi sono scritti (c, c++, c#, java, javascript, ruby, etc). Fino ad arrivare ai linguaggi tipicamente adoperati in Ai come python che sarà adoperato in questo corso [ 4]. Si ha il vantaggio di poter intervenire con un solo IDE per qualunque linguaggio e conservare uno standard di cooperazione durante lo sviluppo. Flow-based programming è il modo più facile ed agevole per unire i vantaggi di un workflow ed un dataflow quando si progetta una applicazione AI. In questo corso si userà Node-RED che è appunto un flow-based programming tool[3].
The role of cloud and distribute computing in CC: PaaS platform as IBM-Watson, Microsoft-Azure, et al
La capacità di sfruttare i servizi di calcolo fortemente distribuiti e a buon mercato non solo ha trasformato il modo con il quale oggi viene gestito e distribuito il software ma è anche diventato un cardine per l’attività di commercializzazione del cognitive computing. Enormi sistemi di elaborazione cognitiva richiedono un ambiente di elaborazione convergente che supporti una varietà di tipi di hardware, servizi software ed elementi di rete che devono essere bilanciati dal carico di lavoro. Pertanto il cloud computing e un'architettura distribuita sono i modelli di base necessari per rendere operativo i sistemi cognitivi su larga scala.
Si passano in rassegna le maggiori Platform as a Service come IBM Watson, Microsoft Azure, Google Ai Platform, etc. Ben sapendo che lo scenario, al momento, mostra almeno una ventina di piattaforme di cognitive computing. Il capitolo prova a delineare criteri di scelta “orientata” ai problemi ed al dominio. In maniera da rendere oggettiva la scelta ma anche osservando altri criteri come i costi, il trattamento dei dati e la loro tenuta e tanti altri criteri che potrebbero risultare prioritari in alcuni contesti.
Building a Watson-enabled system
Si definisce, definite un dominio, un modo originale per ritagliare una architettura di un sistema cognitiva su di un problema, con tutto quello che ciò comporta in termini di bilanciamento delle risorse cloud, di calcolo, di memoria e di scelta della macchina adeguata su cui tutto ciò deve essere implementato e deve essere eseguito. Lo si fa prendendo a riferimento una dei sisstemi cogitivi più diffusi IBM-Watson.
The process of Building a Cognitive application
Costruire una applicazione cognitive non è la stessa cosa che costruire una applicazione software. I sistemi cognitivi sono dirompenti e sconvolgono i paradigmi di progettazione, da ciò nasce l’esigenza di disegnare un modello di processo per lo sviluppo dell’applicazione congnitiva che si diversifica da quello dello sviluppo software in molte parti ed, addirittura, in talune è anche più creativo e completo. La definizione degli obiettivi, la definizione del dominio e la comprensione delle reali intenzioni dell’utente e degli indizi nascosti sono una disciplina molto approfondita nella ingegneria del software, ma la disciplina dell’ingegneria dei sistemi cognitivi necessita di strumenti più semplici e condivisi per le fasi alte di progettazione per questo adopereremo strumenti di design thinking i quali aiutano a condividere le specifiche ed accettare i vincoli di dominio. La definizione delle domande e l’esplorazione degli indizi insieme all’acquisizione delle sorgenti di dati che costituiranno il corpora sarà l’elemento base su cui ruoterà tutto il sistema cognitivo. Il corpora, e questa è una differenza importante, è sempre vivo: una volta creato deve essere continuamente aggiornato perché è su questo che l’applicazione si aggiorna. Infine le tecniche di training e di testing del sistema sono a completare questo capitolo.
Application of cognitive computing to internet of things
Le applicazioni cognitive incontrano l’internet delle cose e la gestione dei dati eterogenei in real time costruendo applicazioni specifiche per la risoluzione di problemi sempre più complessi. La gestione di una città intelligente, la gestione di un applicazione cognitiva per migliorare lo stato di saluto di un paziente ed il suo benessere sono due esempi di applicazioni che passano attraverso la raccolta di dati che provengono da sensori e che devono essere elaborati in tempo utile per consentire ai “decisori” di attivare le giuste decisioni per controllare i problemi.
The operation of AI platform
Per la maggior parte delle organizzazioni, l’integrazione di soluzioni di intelligenza artificiale all’interno dei flussi di lavoro aziendali, rappresenta, ad oggi, un lavoro complesso, costellato di fallimenti . Solo la metà dei progetti di intelligenza artificiale passa dalla fase pilota a quella della produzione. E, i quest’ultimo caso,mediamente servono circa otto-nove mesi per arrivare alla messa a punto completa di un sistema AI efficiente e integrato all’interno della propria operatività, conferendo a tale sistema un valore tangibile nella trasformazione del business. Ebbene, Gartner prevede che, entro il 2025 – complice la sempre maggiore maturità delle tecnologie di AI Orchestration and Automation Platform – il 70% delle aziende avrà reso operative le proprie architetture di intelligenza artificiale, spostando così i progetti AI dall’idea alla produzione e rendendoli, nel concreto, utili.
Efficient Use of resources
Investire nell’intelligenza artificiale significa utilizzare in modo efficiente tutte le risorse a disposizione, compresi i dati e i modelli di calcolo. Un esempio viene proprio dalla composite AI che, coniuga tecniche diverse, tra cui deep learning, analisi dei grafi, modellazione basata su agenti e tecniche di ottimizzazione. Col risultato di un sistema di intelligenza artificiale “composito”, in grado di risolvere una gamma più ampia di problemi aziendali. Ma è necessario che tali tecnologie (e i dati utilizzati per allenare gli algoritmi) vengano usate con la massima efficienza da chi ne possiede le competenze.
Responsible AI
“Una maggiore trasparenza e verificabilità delle tecnologie di intelligenza artificiale continua a rivestire un’importanza cruciale. Questa è l’AI responsabile”. Tanto più necessaria quanto più l’AI arriva a sostituire le decisioni umane su larga scala, amplificando gli impatti positivi e negativi di tali decisioni. L’attenzione deve focalizzarsi sui dati che vengono somministrati alla macchina. Se il dato è “buono”, scevro da pregiudizi, allenerà un algoritmo altrettanto “buono” e libero da bias. L’attenzione, in particolare, deve essere alta nei confronti dei pregiudizi “impliciti”, meno manifesti e, dunque, più difficili da individuare. Come, ad esempio, quelli che conducono a decisioni discriminatorie nei confronti dell’età o del genere. Nei prossimi anni, dunque, le organizzazioni dovranno poter sviluppare e gestire sistemi di intelligenza artificiale “che siamo etici e trasparenti” e, per il conseguimento di tale obiettivo, tutto il personale dedito allo sviluppo di sistemi AI dimostri di possedere esperienza nella “responsible AI”.
Approach that combines small data & wide data
In tema di nuovi trend dell’intelligenza artificiale, un’altra tendenza riguarda i “dati piccoli” (small data), vale a dire quei dati che hanno a che vedere con l’applicazione di tecniche analitiche che necessitano di un numero inferiore di informazioni. Tali dati insieme all’utilizzo di grandi set di dati (wide data o big dta), consentono analisi più approfondite e aiutano a ottenere una visione più a ampia del problema che si intende risolvere per mezzo dell’AI. L’Hype Cycle for Artificial Intelligence 2021 indica che, entro il 2025, il 70% delle organizzazioni sarà costretto a spostare la propria attenzione dai dati grandi a quelli piccoli, conferendo, in questo modo, più spazio all’analisi e all’incrocio dei dati stessi. Si tratta, di una tendenza osservata a partire dalla crisi pandemica, che ha causato un rapido decadere delle grandi mole di dati storici, correlati a situazioni passate, e rompendo, così, schemi precedenti. Adottare tecniche di analisi che coniugano “small data” e “wide data” significa, invece, lavorare con volumi diversi di dati ed estrarre valore da fonti diverse e non strutturate.
MATERIALE DIDATTICO
Indicare i libri di testo consigliati o altro materiale didattico utile.
[0] J.E. Kelly III and S. Hamm, Smart Machines IBM's Watson and the Era of Cognitive Computing (2014), ISBN: 978-0-231-16856-4.
[1] Alfio Gliozzo et al, Building Cognitive Applications with IBM Watson Services: Volume 1 Getting Started, (2017) IBM redbook , https://ibm.co/30V63PU
[2] J. Hurwitz, M. Kaufman, A. Bowles, Cognitive Computing and Big Data Analytics (2015), ISBN: 978-1-118-89662-4.
[3] Taiji Hagino, Practical Node-RED Programming (March 2021), ISBN 978-1-80020-159-0.
[4] Paul Deitel, Harvey Deitel, Intro to Python for Computer Science and data Science, (2020), ISBM-13: 978-0-13-540467-6.
[5] Paolo Maresca Materiale delle lezioni e registrazioni del corso a.a. 2020-2021 COGNITIVE COMPUTING SYSTEMS accesso su Teams con codice tr9xxpl link: https://bit.ly/2SBD0t3
MODALITÀ DI SVOLGIMENTO DELL'INSEGNAMENTO
Il docente utilizzerà lezioni frontali per circa la metà (50%) del corso, la restante parte sarà dedicato (50%) alle esercitazione, seminari ed ai laboratori. I laboratori serviranno ad approfondire gli aspetti teorici e metodologici emersi nelle lezioni frontali. Data la spiccata correlazione del corso con l’evoluzione del cognitive computing, i laboratori potranno essere diversi di anno in anno e saranno chiamati anche esperti di aziende a tenere le tematiche più innovative. Seminari sulle nuove tendenze del cognitive computing, sono altresì previsti.
VERIFICA DI APPRENDIMENTO E CRITERI DI VALUTAZIONE
a) Modalità di esame:
| L'esame si articola in prova: |
| Scritta e orale |
|
| Solo scritta o intercorso a metà |
|
| Solo orale |
 |
| Discussione di elaborato progettuale |
|
| Altro |
|
| In caso di prova scritta i quesiti sono (*): |
| A risposta multipla |
|
| A risposta libera |
|
| Esercizi numerici |
|



")
")





